
Sviluppare un chatbot di livello aziendale utilizzando OpenAI Assistants – Parte 1
Per istruzioni dettagliate sulla creazione di un GPT personalizzato con un’API personalizzata, consultare Parte II.
In breve
I GPT, noti anche come assistenti OpenAI, hanno riscontrato problemi di sicurezza, pertanto, è fondamentale salvaguardare i propri dati.
OpenAI è interessata a ottenere dati di valore (https://openai.com/blog/data-partnerships), in particolare dati di conversazione, che sono più preziosi dei dati grezzi. I dati grezzi sono considerati di bassa qualità rispetto ai dati convesazionali.
- Gli utenti di OpenAI Assistants appartengono a OpenAI, non ai creatori del chatbot. I creatori stanno semplicemente fornendo un servizio a OpenAI.
- Esiste un conflitto di interessi sulla proprietà dei dati tra tutte le parti coinvolte in un chatbot: OpenAI, i creatori e gli utenti. La questione non è stata risolta.
- Per garantire la protezione dei dati durante l’utilizzo degli OpenAI Assistants, si consiglia di sviluppare un’architettura sperimentale a basso costo.
- Come si può accedere alla conversazione completa?
Idee fondamentali per lo sviluppo di un chatbot affidabile e protetto:
- Estrazione dei dati: Comprendere le entità interessate ai vostri dati e le loro motivazioni.
- Prevenzione della fuga di dati: A causa della dispersione degli OpenAI Assistant, è fondamentale proteggere i dati sensibili nascondendoli dietro l’API per evitare qualsiasi esposizione involontaria.
- Ottimizzazione dell’API: L’utilizzo di OpenAI Actions può indirizzare le chiamate API a un aggregatore API, contribuendo a limitare la quantità di dati restituiti e a ridurre l’utilizzo di token. Anche la personalizzazione dell’API per fornire solo i dati necessari può migliorare l’efficienza.
- Garantire la sicurezza: L’accesso a specifiche API deve essere limitato alle richieste autorizzate per mantenere la sicurezza e l’integrità del chatbot.
- Monitoraggio: Il monitoraggio regolare dei log, del traffico e delle richieste è essenziale per identificare eventuali problemi e ottimizzare le prestazioni.
- Sviluppare una comprensione dei clienti e delle loro interazioni con il chatbot per migliorarne la funzionalità. Potrebbe non essere quello che si pensava inizialmente.
- Stiamo attualmente esplorando la possibilità di comprimere il traffico per semplificare la comunicazione tra il chatbot e i server. Questo aspetto è ancora in fase di test per verificarne l’efficacia e l’impatto.
Recupero dei dati
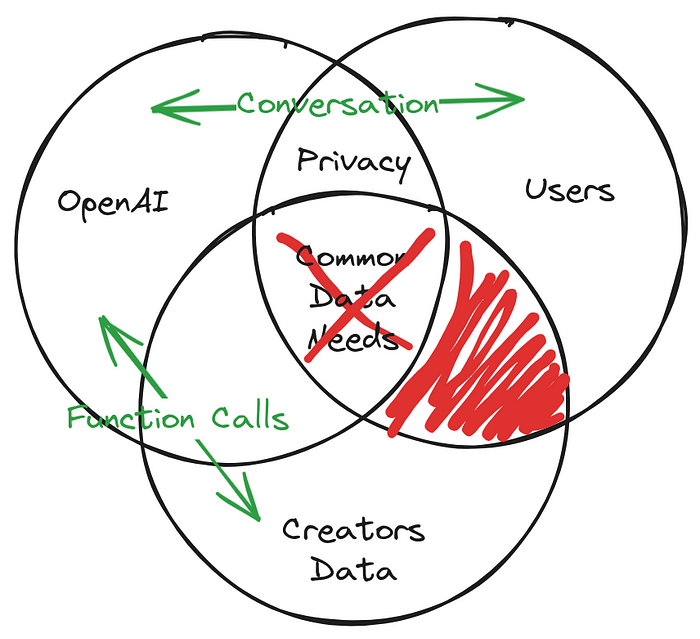
All’interno dell’ecosistema di dati di un assistente chatbot, ci sono tre ruoli importanti: il fornitore del chatbot (OpenAI), gli utenti del chatbot OpenAI e il creatore del chatbot.
Il concetto di “privacy” è un punto di intersezione importante per tutte e tre le entità. C’è una sezione condivisa alla salvaguardia della privacy, che evidenzia l’enfasi di OpenAI sulla protezione dell’anonimato degli utenti, promuovendo al contempo discussioni significative.
Il creatore si trova di fronte a un dilemma: è escluso dalla conversazione e non può trarne alcun insegnamento, il che lo pone in una posizione di svantaggio. È discutibile il motivo per cui una persona dovrebbe condividere le proprie informazioni riservate con la piattaforma. Quali vantaggi ne trae il creatore?
Quando si cerca di bilanciare le esigenze di dati di OpenAI, dei suoi utenti e dei creatori, sorge un conflitto. Ciò richiede una rivalutazione del modo in cui vengono soddisfatte le esigenze di dati, al fine di soddisfare tutte le parti senza violare gli obiettivi individuali o gli standard di privacy.
Strategie per prevenire le fughe di dati
Secondo l’articolo “Creators are Leaking Their Data by Using Custom GPTs”, gli assistenti OpenAI sono suscettibili di possibili Leaks. Per evitare l’esposizione involontaria dei dati, è essenziale salvaguardare i dati sensibili nascondendoli dietro l’API. È possibile per chiunque accedere ai prompt e ai dati di origine memorizzati in OpenAI, per cui è fondamentale impiegare metodi di offuscamento per nascondere i dati e i prompt agli utenti.
Attraverso l’utilizzo di OpenAI Actions, diventa possibile nascondere una parte delle richieste all’interno di un’API. Inoltre, con l’utilizzo di un aggregatore di API, è possibile nascondere l’API agli utenti finali.
Migliorare le prestazioni dell’API
L’uso di “actions” personalizzate OpenAI permette di utilizzare API esterne, consentendo ai GPT di incorporare informazioni esterne e di interagire con il mondo fisico. I GPT possono essere collegati a database, integrati con le e-mail o addirittura fungere da assistenti agli acquisti. Ad esempio, si può integrare un database di annunci di viaggio, collegare l’account di posta elettronica di un utente o facilitare le transazioni di e-commerce.
L’utilizzo di un aggregatore di API, piuttosto che la connessione diretta alle API, può aiutare a limitare la quantità di dati recuperati e di conseguenza a ridurre l’utilizzo dei token. Inoltre, personalizzare l’aggregatore di API in modo che restituisca solo i dati essenziali può migliorare ulteriormente l’efficienza.
Nel caso in cui si utilizzi un aggregatore di API per recuperare un elenco completo di utenti, è possibile utilizzare OpenAI Actions per indirizzare la richiesta all’aggregatore e recuperare solo i dati relativi agli utenti desiderati. Questo approccio comporterebbe una riduzione della quantità di dati restituiti e, di conseguenza, una diminuzione del numero di token utilizzati.
Allo stesso modo, è possibile modificare l’aggregatore API per fornire esclusivamente i dati necessari. Ad esempio, se il nome e l’indirizzo e-mail dell’utente sono le uniche informazioni rilevanti, l’API può essere personalizzata per recuperare esclusivamente questi dati. In questo modo si ridurrebbe notevolmente la quantità di dati restituiti e, di conseguenza, il numero di token utilizzati.
Una possibile soluzione potrebbe essere quella di utilizzare un aggregatore di API, che unisca le informazioni provenienti da più API su meteo, traffico e notizie, per fornire i dati necessari al chatbot.
In generale, la personalizzazione delle API può ridurre la quantità di dati ricevuti e, di conseguenza, l’utilizzo dei token. Questo può tradursi in una maggiore efficacia e in vantaggi finanziari.
Protezione delle informazioni
Proteggete i vostri dati dall’essere consumati da OpenAI in ogni momento, come indicato in questo articolo sulle sue abitudini di consumo dei dati a colazione, pranzo e cena. Il design sperimentale della nostra architettura impiega tecniche di offuscamento e separazione per garantire la sicurezza dei vostri dati.
Monitoraggio
A ogni livello dell’architettura, il monitoraggio è attivato. Questo include una combinazione di processi automatizzati e di implementazione attraverso la codifica nel vostro aggregatore di API.
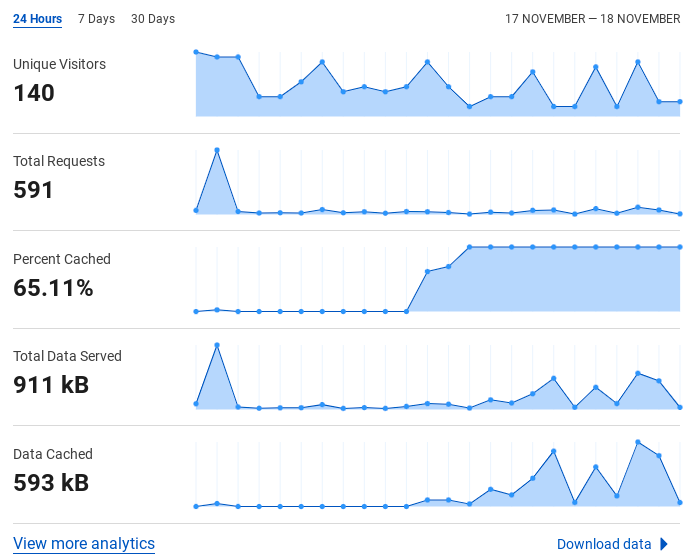
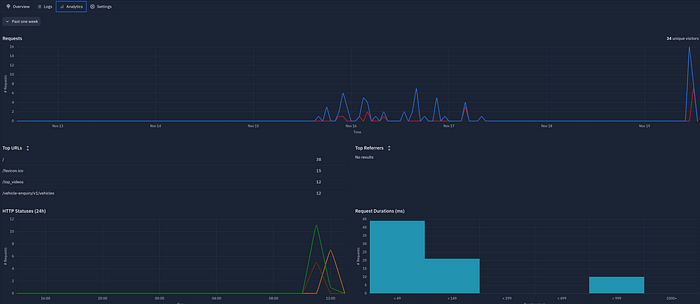
Analisi da Replit
Modello di architettura sperimentale
Il diagramma seguente illustra una strategia sofisticata e a più livelli per la gestione e la salvaguardia dei dati.
Il principio fondamentale di questo innovativo progetto architettonico è quello di dare priorità alla salvaguardia dei dati e dei servizi dell’infrastruttura.
Secondo quanto riportato, ci sono più di 100 milioni di persone che utilizzano OpenAI e un chatbot molto utilizzato potrebbe potenzialmente sovraccaricare il sistema attuale. È stato scoperto che diversi individui sfruttano i chatbot accedendo alle loro richieste e fonti di dati.
Secondo le domande di brevetto di OpenAI, la loro architettura ha il potenziale per accogliere i prossimi progressi, indicando la loro preparazione per modelli di IA più sofisticati che possono utilizzare efficacemente i dati sicuri e di alta qualità.
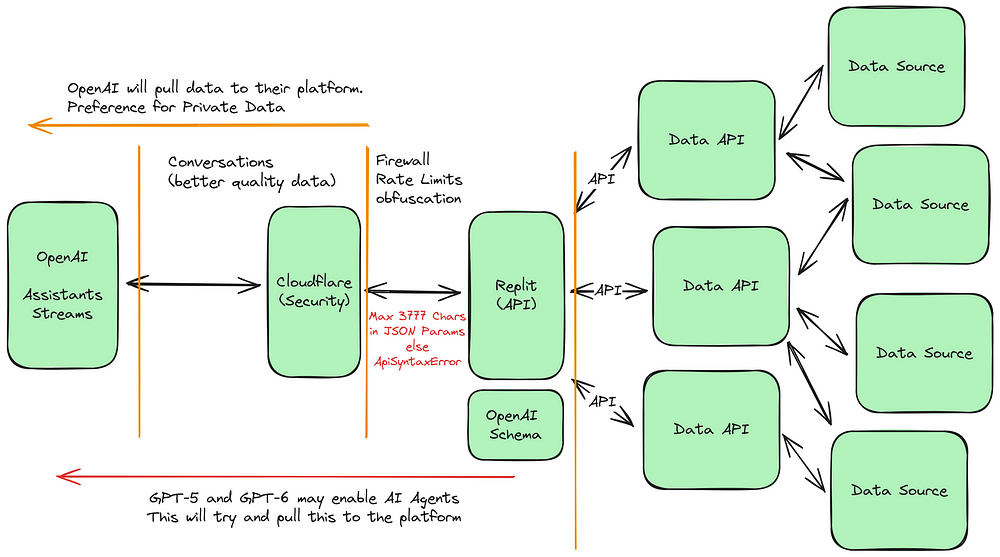
Sicurezza Cloudflare
Al centro del meccanismo di sicurezza c’è Cloudflare, una forte barriera difensiva che offre misure di protezione come la protezione DDoS, i servizi di firewall e la limitazione della velocità.
Grazie all’utilizzo di Cloudflare DNS, siamo in grado di salvaguardare i nostri servizi API da possibili attacchi DDoS nascondendo i loro indirizzi IP.
In questo modo si garantisce la protezione dei dati da pericoli esterni e si dispone di un sistema regolamentato per l’accesso e la circolazione.
Le seguenti funzionalità sono fornite da Cloudflare:
- Per garantire un accesso sicuro ai servizi API, saranno implementate regole IP per limitare l’accesso solo attraverso OpenAI.
- Le API e le fonti di dati saranno protette da una limitazione della velocità per evitare un uso eccessivo.
- Saranno adottate misure di protezione contro gli attacchi DDoS.
- Verranno impostati i DNS per i servizi API.
- Verranno applicati i protocolli TLS e HTTPS per garantire una comunicazione sicura.
- Saranno messi in atto meccanismi di caching per migliorare le prestazioni.
- Il sistema sarà monitorato, registrato e analizzato per comprendere meglio il suo utilizzo.
- In futuro, c’è la possibilità di espandere il servizio incorporando servizi Cloudflare come Workers, R2, ecc.
L’aggregatore di API su Replit è uno strumento che combina diverse API in un’unica piattaforma.
Il progetto di questo sistema è incentrato su un livello API fornito da Replit, una piattaforma di codifica collaborativa che opera attraverso un browser web. Questa API funge da connettore tra OpenAI e varie fonti di dati, consentendo l’integrazione di dati esterni nell’ecosistema di OpenAI. Queste API svolgono un ruolo cruciale nel trasferimento di dati da numerose fonti, consentendo a OpenAI di utilizzare un’ampia gamma di informazioni e garantendo al contempo la sicurezza e l’accuratezza dei dati.
Grazie a questa funzione, è possibile generare un’API specifica per i requisiti di dati del chatbot, fornendo esclusivamente i dati necessari per la richiesta.
Come risultato;
- Per ridurre al minimo il numero di chiamate API effettuate dal chatbot, è necessario integrare più API per ottenere le informazioni necessarie.
- È possibile implementare strategie per limitare la quantità di token inviati a OpenAI, restituendo solo i dati rilevanti per la richiesta. Ciò contribuisce a ridurre il numero di token e la latenza.
- La latenza può essere ridotta attraverso l’uso del caching.
- Questo permette di utilizzare vari metodi e algoritmi di prompting che attualmente non sono offerti da OpenAI.
- È possibile comprimere il traffico? (richiede una verifica).
LLM – OpenAI
L’attuale architetto è a favore di OpenAI, ma può essere facilmente sostituito da un altro LLM. Le capacità di LLM stanno avanzando rapidamente e dobbiamo assicurarci di poter supportare qualsiasi progresso futuro.
API per i dati
Potete accedere ai vostri dati e servizi attraverso queste API già esistenti.
Fonte dei dati
Questa è la vostra attuale fonte di dati.
Conclusione
Per creare un chatbot adatto all’uso aziendale utilizzando OpenAI, è necessaria una strategia diversificata. Dando la priorità a una gestione efficace dei dati, alla loro salvaguardia e al loro monitoraggio, le aziende possono utilizzare le capacità complete dell’IA garantendo la riservatezza dei dati e l’ottimizzazione delle operazioni. Tenete gli occhi aperti per ulteriori aggiornamenti e prospettive, mentre continuiamo a spingere i confini dell’IA nelle implementazioni aziendali.
Quella che segue è una guida su come implementare questa architettura. Tenete d’occhio gli aggiornamenti su come ottenere l’accesso alla conversazione completa.

Gabriele Ferrari
Via Cesare Costa,88
41123 – Modena
Nato il 10/06/1968
Tel. +39 3357682392
P.IVA 03615520362
E-mail: gabriele@gabrieleferrari.net
Web Designer, Digital Project Manager, Esperto di WordPress, Sviluppatore Web, Esperto Certificato di Google Ads, Social Media Manager e Graphic Designer attualmente lavora come libero professionista. Fornisce servizi quali consulenza, sviluppo di siti web, SEO e pubblicità online, marketing sui social media, grafica e sviluppo di app mobile per aziende e privati. Precedente esperienza come Web Project Manager e Social Marketing Manager in importanti agenzie web, nonché Family Banker e Team Manager nel settore dei giochi. Laureato presso la facoltà di Ingegneria Elettronica dell’Università di Bologna.

